Publications

Abstract
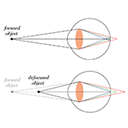
The human eye changes focus---accommodates---to minimize blur in the retinal image. Previous work has shown that stimulation of non-foveal retina can produce accommodative responses when no competing stimulus is presented to the fovea. In everyday situations it is very common for the fovea and other parts of the retina to be stimulated simultaneously. We examined this situation by asking how non-foveal retina contributes to accommodation when the fovea is also stimulated. There were three experimental conditions. 1) Real change in which stimuli of different sizes, centered on the fovea, were presented at different optical distances. Accommodation was, as expected, robust because there was no conflicting stimulation of other parts of the retina. 2) Simulated change, no conflict in which stimuli of different sizes, again centered on the fovea, were presented at different simulated distances using rendered chromatic blur. Accommodation was robust in this condition because there was no conflict between the central and peripheral stimuli. 3) Simulated change, conflict in which a central disk (of different diameters) was presented along with an abutting peripheral annulus. The disk and annulus underwent opposite changes in simulated distance. Here we observed a surprisingly consistent effect of the peripheral annulus. For example, when the diameter of the central stimulus was 8° (thereby stimulating the fovea and parafovea), the abutting peripheral annulus had a significant effect on accommodation. We discuss how these results may help us understand other situations in which non-fixated targets affect the ability to focus on a fixated target. We also discuss potential implications for the development of myopia and for foveated rendering.
Abstract
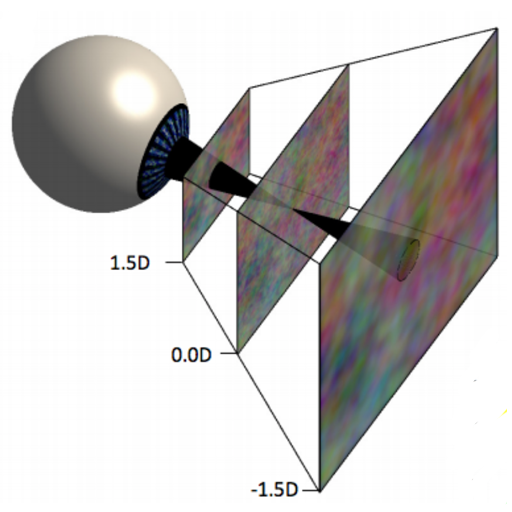
Blur occurs naturally when the eye is focused at one distance and an object is presented at another distance. Computer-graphics engineers and vision scientists often wish to create display images that reproduce such depth-dependent blur, but their methods are incorrect for that purpose. They take into account the scene geometry, pupil size, and focal distances, but do not properly take into account the optical aberrations of the human eye. We developed a method that, by incorporating the viewer's optics, yields displayed images that produce retinal images close to the ones that occur in natural viewing. We concentrated on the effects of defocus, chromatic aberration, astigmatism, and spherical aberration and evaluated their effectiveness by conducting experiments in which we attempted to drive the eye's focusing response (accommodation) through the rendering of these aberrations. We found that accommodation is not driven at all by conventional rendering methods, but that it is driven surprisingly quickly and accurately by our method with defocus and chromatic aberration incorporated. We found some effect of astigmatism but none of spherical aberration. We discuss how the rendering approach can be used in vision science experiments and in the development of ophthalmic/optometric devices and augmented- and virtual-reality displays.
Abstract
Two dilemmas arise in inferring shape information from shading. First, depending on the rendering physics, images can change significantly with (even) small changes in lighting or viewpoint, while the percept frequently does not. Second, brightness variations can be induced by material effects—such as pigmentation—as well as by shading effects. Improperly interpreted, material effects would confound shading effects. We show how these dilemmas are coupled by reviewing recent developments in shape inference together with a role for colour in separating material from shading effects. Aspects of both are represented in a common geometric (flow) framework, and novel displays of hue/shape interaction demonstrate a global effect with interactions limited to localized regions. Not all parts of an image are perceptually equal; shape percepts appear to be constructed from image anchor regions.

Abstract
Computer-graphics engineers and vision scientists want to generate images that reproduce realistic depth-dependent blur. Current rendering algorithms take into account scene geometry, aperture size, and focal distance, and they produce photorealistic imagery as with a high-quality camera. But to create immersive experiences, rendering algorithms should aim instead for perceptual realism. In so doing, they should take into account the significant optical aberrations of the human eye. We developed a method that, by incorporating some of those aberrations, yields displayed images that produce retinal images much closer to the ones that occur in natural viewing. In particular, we create displayed images taking the eye's chromatic aberration into account. This produces different chromatic effects in the retinal image for objects farther or nearer than current focus. We call the method ChromaBlur. We conducted two experiments that illustrate the benefits of ChromaBlur. One showed that accommodation (eye focusing) is driven quite effectively when ChromaBlur is used and that accommodation is not driven at all when conventional methods are used. The second showed that perceived depth and realism are greater with imagery created by ChromaBlur than in imagery created conventionally. ChromaBlur can be coupled with focus-adjustable lenses and gaze tracking to reproduce the natural relationship between accommodation and blur in HMDs and other immersive devices. It may thereby minimize the adverse effects of vergence-accommodation conflicts.
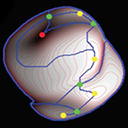
Abstract
The interpretation of other agents as intentional actors equipped with mental states has been connected to the attribution of rationality to their behavior. But a workable definition of “rationality” is difficult to formulate in complex situations, where standard normative definitions are difficult to apply. In this study, we explore a notion of rationality based on the idea of evolutionary fitness. We ask whether agents that are more adapted to their environment are, consequently, perceived as more rational and intentional. We created a 2-D virtual environment populated with autonomous virtual agents, each of which behaves according to a built-in program equipped with simulated perception, memory, and decision making. We then introduced a process of simulated evolution that pressured the agents’ programs toward behavior more adapted to the simulated environment. We showed these agents to human subjects in 2 experiments, in which we respectively asked them to judge their intelligence and to dynamically estimate their “mental states.” The results confirm that subjects construed evolved agents as more intelligent, and judged evolved agents’ mental states more accurately, relative to nonevolved agents. These results corroborate a view that the interpretation of agent behavior is connected to a concept of rationality based on the apparent fit between an agent’s actions and its environment.

Abstract
Humans can judge from vision alone whether an object is physically stable or not. Such judgments allow observers to predict the physical behavior of objects, and hence to guide their motor actions. We investigated the visual estimation of physical stability of 3-D objects (shown in stereoscopically viewed rendered scenes) and how it relates to visual estimates of their center of mass (COM). In Experiment 1, observers viewed an object near the edge of a table and adjusted its tilt to the perceived critical angle, i.e., the tilt angle at which the object was seen as equally likely to fall or return to its upright stable position. In Experiment 2, observers visually localized the COM of the same set of objects. In both experiments, observers' settings were compared to physical predictions based on the objects' geometry. In both tasks, deviations from physical predictions were, on average, relatively small. More detailed analyses of individual observers' settings in the two tasks, however, revealed mutual inconsistencies between observers' critical-angle and COM settings. The results suggest that observers did not use their COM estimates in a physically correct manner when making visual judgments of physical stability.
Abstract
We examined the perception of virtual curved surfaces explored with a tool. We found a reliable curvature aftereffect, suggesting neural representation of the curvature in the absence of direct touch. Intermanual transfer of the aftereffect suggests that this representation is somewhat independent of the hand used to explore the surface.

Abstract
Inferring the mental states of other agents, including their goals and intentions, is a central problem in cognition. A critical aspect of this problem is that one cannot observe mental states directly, but must infer them from observable actions. To study the computational mechanisms underlying this inference, we created a two-dimensional virtual environment populated by autonomous agents with independent cognitive architectures. These agents navigate the environment, collecting "food" and interacting with one another. The agents' behavior is modulated by a small number of distinct goal states: attacking, exploring, fleeing, and gathering food. We studied subjects' ability to detect and classify the agents' continually changing goal states on the basis of their motions and interactions. Although the programmed ground truth goal state is not directly observable, subjects' responses showed both high validity (correlation with this ground truth) and high reliability (correlation with one another). We present a Bayesian model of the inference of goal states, and find that it accounts for subjects' responses better than alternative models. Although the model is fit to the actual programmed states of the agents, and not to subjects' responses, its output actually conforms better to subjects' responses than to the ground truth goal state of the agents.

Abstract
Visual estimation of object stability is an ecologically important judgment that allows observers to predict the physical behavior of objects. A natural method that has been used in previous work to measure perceived object stability is the estimation of perceived "critical angle"—the angle at which an object appears equally likely to fall over versus return to its upright stable position. For an asymmetric object, however, the critical angle is not a single value, but varies with the direction in which the object is tilted. The current study addressed two questions: (a) Can observers reliably track the change in critical angle as a function of tilt direction? (b) How do they visually estimate the overall stability of an object, given the different critical angles in various directions? To address these questions, we employed two experimental tasks using simple asymmetric 3D objects (skewed conical frustums): settings of critical angle in different directions relative to the intrinsic skew of the 3D object (Experiment 1), and stability matching across 3D objects with different shapes (Experiments 2 and 3). Our results showed that (a) observers can perceptually track the varying critical angle in different directions quite well; and (b) their estimates of overall object stability are strongly biased toward the minimum critical angle (i.e., the critical angle in the least stable direction). Moreover, the fact that observers can reliably match perceived object stability across 3D objects with different shapes suggests that perceived stability is likely to be represented along a single dimension.

Abstract
Two-interval two-alternative forced-choice discrimination experiments were conducted separately for sinusoidal and triangular textured surface gratings from which amplitude (i.e., height) discrimination thresholds were estimated. Participants (group sizes: n = 4 to 7) explored one of these texture types either by fingertip on real gratings (Finger real), by stylus on real gratings (Stylus real), or by stylus on virtual gratings (Stylus virtual). The real gratings were fabricated from stainless steel by an electrical discharge machining process while the virtual gratings were rendered via a programmable force-feedback device. All gratings had a 2.5-mm spatial period. On each trial, participants compared test gratings with 55, 60, 65, or 70 μm amplitudes against a 50-μm reference. The results indicate that discrimination thresholds did not differ significantly between sinusoidal and triangular gratings. With sinusoidal and triangular data combined, the average (mean + standard error) for the Stylus-real threshold (2.5 +- 0.2 μm) was significantly smaller (p < 0.01) than that for the Stylus-virtual condition (4.9 +- 0.2 μm). Differences between the Finger-real threshold (3.8 +- 0.2 μm) and those from the other two conditions were not statistically significant. Further studies are needed to better understand the differences in perceptual cues resulting from interactions with real and virtual gratings.

Abstract
The detectability and discriminability of virtual haptic gratings were analyzed in the frequency domain. Detection (Exp. 1) and discrimination (Exp. 2) thresholds for virtual haptic gratings were estimated using a force-feedback device that simulated sinusoidal and square-wave gratings with spatial periods from 0.2 to 38.4 mm. The detection threshold results indicated that for spatial periods up to 6.4 mm (i.e., spatial frequencies >0.156 cycle/mm), the detectability of square-wave gratings could be predicted quantitatively from the detection thresholds of their corresponding fundamental components. The discrimination experiment confirmed that at higher spatial frequencies, the square-wave gratings were initially indistinguishable from the corresponding fundamental components until the third harmonics were detectable. At lower spatial frequencies, the third harmonic components of square-wave gratings had lower detection thresholds than the corresponding fundamental components. Therefore, the square-wave gratings were detectable as soon as the third harmonic components were detectable. Results from a third experiment where gratings consisting of two superimposed sinusoidal components were compared (Exp. 3) showed that people were insensitive to the relative phase between the two components. Our results have important implications for engineering applications, where complex haptic signals are transmitted at high update rates over networks with limited bandwidths.

Abstract
Augmented reality (AR) is gaining momentum, with multiple commercial see-through near-eye displays arriving such as the Meta 2 and the Microsoft Hololens. These devices are a big step toward Ivan Sutherland’s original vision of an "ultimate display", but many limitations remain. Existing displays struggle to achieve a wide field of view (FOV) with compact optics. Such displays also suffer from the vergence-accommodation conflict: they present synthetic images at a constant optical distance, requiring a fixed focus from the eye's accommodation mechanism, while the vergence of the two eyes working in concert places the synthetic object(s) at a distance other than the accommodation distance. This project employs a novel wide-FOV optical design that can adjust the focus depth dynamically, tracking the user's binocular gaze and matching the focus to the vergence. Thus the display is always "in focus" for whatever object the user is looking at, solving the vergence-accommodation conflict. Objects at a different distance, which should not be in focus, are rendered with a sophisticated simulated defocus blur that accounts for the internal optics of the eye.

Abstract
Comprehension of goal-directed, intentional motion is an important but understudied visual function. To study it, we created a two-dimensional virtual environment populated by independently-programmed autonomous virtual agents, which navigate the environment, collecting food and competing with one another. Their behavior is modulated by a small number of distinct "mental states": exploring, gathering food, attacking, and fleeing. In two experiments, we studied subjects' ability to detect and classify the agents’ continually changing mental states on the basis of their motions and interactions. Our analyses compared subjects’ classifications to the ground truth state occupied by the observed agent’s autonomous program. Although the true mental state is inherently hidden and must be inferred, subjects showed both high validity (correlation with ground truth) and high reliability (correlation with one another). The data provide intriguing evidence about the factors that influence estimates of mental state—a key step towards a true "psychophysics of intention."

Abstract
As haptics becomes an integral component of scientific data visualization systems, there is a growing need to study "haptic glyphs" (building blocks for displaying information through the sense of touch) and quantify their information transmission capability. The present study investigated the channel capacity for transmitting information through stiffness or force magnitude. Specifically, we measured the number of stiffness or force- magnitude levels that can be reliably identified in an absolute identification paradigm. The range of stiffness and force magnitude used in the present study, 0.2-3.0 N/mm and 0.1-5.0 N, respectively, was typical of the parameter values encountered in most virtual reality or data visualization applications. Ten individuals participated in a stiffness identification experiment, each completing 250 trials. Subsequently, four of these individuals and six additional participants completed 250 trials in a force-magnitude identification experiment. A custom-designed 3 degrees-of-freedom force-feedback device, the ministick, was used for stimulus delivery. The results showed an average information transfer of 1.46 bits for stiffness identification, or equivalently, 2.8 correctly-identifiable stiffness levels. The average information transfer for force magnitude was 1.54 bits, or equivalently, 2.9 correctly-identifiable force magnitudes. Therefore, on average, the participants could only reliably identify 2-3 stiffness levels in the range of 0.2-3.0 N/mm, and 2-3 force- magnitude levels in the range of 0.1-5.0 N. Individual performance varied from 1 to 4 correctly-identifiable stiffness levels and 2 to 4 correctly-identifiable force-magnitude levels. Our results are consistent with reported information transfers for haptic stimuli. Based on the present study, it is recommended that 2 stiffness or force-magnitude levels (i.e., high and low) be used with haptic glyphs in a data visualization system, with an additional third level (medium) for more experienced users.

Abstract
The tactile detectability of sinusoidal and square-wave virtual texture gratings were measured and analyzed. Using a three-interval one-up three-down adaptive tracking procedure, detection thresholds for virtual gratings were estimated using a custom-designed high position-resolution 3-degrees-of-freedom force-feedback haptic device. Two types of gratings were used, defined by sinusoidal and square waveforms, with spatial wavelengths of 0.2 to 25.6 mm. The results indicated that the participants demonstrated a higher sensitivity (i.e., lower detection threshold) to square-wave gratings than to sinusoidal ones at all the wavelengths tested. When the square-wave gratings were represented by the explicative Fourier series, it became apparent that the detectability of the square-wave gratings could be determined by that of the sinusoidal gratings at the corresponding fundamental frequencies. This was true for any square-wave grating as long as the detection threshold for the fundamental component was below those of the harmonic components.

Abstract
In computer-generated imagery and vision science, defocus blur is often rendered to simulate objects closer or farther than the focal plane. But depth-dependent optical effects, like longitudinal chromatic aberration (LCA), are not implemented in a physically correct manner. Recent evidence has shown that incorporating LCA into rendered images produces a powerful cue for driving accommodation and depth perception. But implementing correct LCA effects is computationally expensive. Applied implementations of defocus blur with LCA are possible, but require approximations in order to run in real-time. We investigated whether real-time implementation of blur with LCA using approximate blur kernels and simplified treatment of occlusions can still drive accommodation and improve perceived depth compared to conventional methods that do not incorporate LCA. We measured accommodative responses with an autorefractor while participants viewed stimuli at various real and simulated distances. For real changes, a focus-tunable lens altered the optical distance of the stimulus, producing a blurred retinal image with the observer's natural aberrations. For simulated changes, optical distance was constant and rendered image content changed. These stimuli were generated using 1) conventional defocus blur with all color channels treated the same; 2) defocus blur and LCA with each channel treated correctly; or 3) approximate defocus and LCA using truncated 2D Gaussian blur kernels within a real-time game engine. Simulated changes in defocus with LCA (both physically accurate and real-time) drove accommodation as well as real changes. In another experiment, participants viewed images with two planes, one partially occluding the other, and made relative depth judgments. Incorporating physically correct rendered LCA or real-time approximations improved depth ordering relative to conventional techniques that do not incorporate LCA. Chromatic information is important for accommodation and depth perception and can be implemented in real-time applications.

Abstract
Purpose: Experiments suggest that hyperopic focus in the peripheral retina increases the risk of developing myopia. This implies that signed defocus can trigger eye growth. But does this mean blur in the periphery affects other oculomotor mechanisms such as accommodation? Stimulation of the human peripheral retina when no foveal stimulus is present elicits accommodation. But in natural viewing, the fovea and periphery are nearly always both stimulated. We investigated accommodative responses when the fovea and periphery are both stimulated, but with different signs of defocus.
Methods: 10 participants (18-25 yrs) viewed black-white textures monocularly. The stimuli varied in depth (±1.5D) sinusoidally (0.1, 0.2, 0.5, or 1.0Hz). Three conditions were tested: Real Blur, Defocus+LCA, and Defocus+LCA Conflict. In Real Blur, the optical distance of the textures (disks subtending 1, 2, 4, 6, 8, or 14°) was varied using a focus-tunable lens. For Defocus+LCA, the textures (again 1, 2, 4, 6, 8, or 14°) were rendered using simulated defocus with color-correct longitudinal chromatic aberration (LCA), a cue that drives accommodation. For Defocus+LCA Conflict, stimuli were split into two abutting regions, a variable sized central disk (1, 2, 4, 6, or 8°) and a peripheral annulus (14° outer radius), both rendered using defocus blur with LCA. The central and peripheral regions had equal magnitudes but opposite signs, signaled by LCA. Accommodative responses were measured at 30Hz with an open-field autorefractor. The data were fit with sinusoids to estimate response gain and phase.
Results: Gains for the Real Blur and Defocus+LCA conditions were similar and consistent across stimulus sizes. Gain for Defocus+LCA Conflict were significantly lower when the central stimulus was smaller than 6°. Phase was consistent with the peripheral stimulus, not the foveal stimulus when the central stimulus was smaller than 4°.
Conclusions: When a small foveal stimulus (4° or smaller) was presented in conflict with a peripheral stimulus, response was dominated by the peripheral signal. Thus accommodation is determined by both foveal and peripheral stimulation when both are present. This observation has important implications for myopia prognosis and treatment and for computer-graphics techniques like foveated rendering.
Abstract
We developed a rendering method that takes into account the eye’s chromatic aberration. Accommodation is driven much more accurately with this method than with conventional methods. Perceived realism is also improved.

Abstract
Blur occurs naturally when the eye is focused at one distance and an object is present at another distance. Vision scientists and computer-graphics (CG) engineers often wish to create display images that reproduce such depth-dependent blur, but their method is incorrect for that purpose. Their method appropriately takes into account the scene geometry, pupil size, and focus distances, but does not take into account the optical aberrations of the person who will view the resulting display images. We developed a method that, by incorporating the viewer’s optics, yields displayed images that produce retinal images close to those in natural viewing. Here we concentrate on the effects of longitudinal chromatic aberration. This aberration creates different chromatic effects in the retinal image for object farther vs nearer than current focus. Our method handles this correctly. Observers viewed scenes with depth-dependent blur. They viewed stimuli monocularly in three conditions: 1) A plane at one physical focal distance but various amounts of blur, rendered conventionally, simulating planes at different distances; 2) a plane at one focal distance but blur rendered using our method, creating natural depth-dependent chromatic effects in the retina; 3) multiple planes at different focal distances, so blur is created in natural fashion in the subject’s eye. We measured accommodation and perception of depth order in these conditions. Accommodation was not driven with the conventional blur-rendering method, but it was driven with equal accuracy by real and simulated changes in focal distance when simulated changes were based on our method. We also found that depth-order judgments were random with conventional rendering of blur, but were quite accurate when the blur was created naturally in the eye or with our rendering method. Thus, creating display images that produce retinal images like those that occur naturally enables accommodation and facilitates depth perception.
Abstract
Accommodation is the process by which the eye lens changes optical power to maintain a clear retinal image as the distance to the fixated object varies. Although luminance blur has long been considered the driving feature for accommodation, it is by definition unsigned (i.e., there is no difference between the defocus of an object closer or farther than the focus distance). Nonetheless, the visual system initially accommodates in the correct direction, implying that it exploits a cue with sign information. Here, we present a model of accommodation control based on such a cue: Longitudinal Chromatic Aberration (LCA). The model relies on color-opponent units, much like those observed among retinal ganglion cells, to make the computation required to use LCA to drive accommodation.
Abstract
The visual system can infer 3D shape from orientation flows arising from both texture and shading patterns. However, these two types of flows provide fundamentally different information about surface structure. Texture flows, when derived from distinct elements, mainly signal first-order features (surface slant), whereas shading flow orientations primarily relate to second-order surface properties (the change in surface slant). The source of an image's structure is inherently ambiguous, it is therefore crucial for the brain to identify whether flow patterns originate from texture or shading to correctly infer shape from a 2D image. One possible approach would be to use 'surface appearance' (e.g. smooth gradients vs. fine-scale texture) to distinguish texture from shading. However, the structure of the flow fields themselves may indicate whether a given flow is more likely due to first- or second-order shape information. We test these two possibilities in this set of experiments, looking at speeded and free responses.

Abstract
Perceiving 3D shape involves processing and combining different cues, including texture, shading, and specular reflections. We have previously shown that orientation flows produced by the various cues provide fundamentally different information about shape, leading to complementary strengths and weaknesses (see Cholewiak & Fleming, VSS 2013). An important consequence of this is that a given shape may appear different, depending on whether it is shaded or textured, because the different cues reveal different shape features. Here we sought to predict specific regions of interest (ROIs) within shapes where the different cues lead to better or worse shape perception. Since the predictions were derived from the orientation flows, our analysis provides a key test of how and when the visual system uses orientation flows to estimate shape. We used a gauge figure experiment to evaluate shape perception. Cues included Lambertian shading, isotropic 3D texture, both shading and texture, and pseudo-shaded depth maps. Participant performance was compared to a number of image and scene-based perceptual performance predictors. Shape from texture ROI models included theories incorporating the surface's slant and tilt, second-order partial derivatives (i.e., change in tilt direction), and tangential and normal curvatures of isotropic texture orientation. Shape from shading ROI models included image based metrics (e.g., brightness gradient change), anisotropy of the second fundamental form, and surface derivatives. The results confirm that individually texture and shading are not diagnostic of object shape for all locations, but local performance correlates well with ROIs predicted by first and second-order properties of shape. The perceptual ROIs for texture and shading were well predicted via the mathematical models. In regions that were ROI for both cues, shading and texture performed complementary functions, suggesting that a common front-end based on orientation flows can predict both strengths and weaknesses of different cues at a local scale.

Abstract
Cracks, crevices and other surface concavities are typically dark places where both dirt and shadows tend to get trapped. By contrast, convex features are exposed to light and often get buffed a lighter or more glossy shade through contact with other surfaces. This means that in many cases, for complex surface geometries, shading and pigmentation are spatially correlated with one another, with dark concavities that are dimly illuminated and lighter convexities, which are more brightly shaded. How does the visual system distinguish between pigmentation and shadows when the two are spatially correlated? We performed a statistical analysis of complex rough surfaces under illumination conditions that varied parametrically from highly directional to highly diffuse in order to characterise the relationships between shading, illumination and shape. Whereas classical shape from shading analyses relate image intensities to surface orientations and depths, here, we find that intensity information also carries important additional cues to surface curvature. By shifting the phase of dark portions of the image relative to the surface geometry, we show that the visual system uses these relationships between curvatures and intensities to distinguish between shadows and pigmentation. Interestingly, we also find that the visual system is remarkably good at separating pigmentation and shadows even when they are highly correlated with one another, as long as the illumination conditions provide subtle local image orientation cues to distinguish the two. Together, these findings provide key novel constraints on computational models of human shape from shading and lightness perception.

Abstract
Humans can judge from vision alone whether an object is physically stable or is likely to fall. This ability allows us to predict the physical behavior of objects, and hence to guide motor actions. We examined observers’ ability to visually estimate the physical stability of 3D objects (conical frustums of varying shapes and sizes), and how these relate to their estimates of center of mass (COM). In two experiments, observers stereoscopically viewed a rendered scene containing a table and a 3D object placed near the table’s edge. In the first experiment, they adjusted the tilt of the object to set its critical angle -- where the object is equally likely to fall off vs. return to its upright stable position. In the second experiment, observers localized the objects’ COM. In both experiments, observers’ performance was compared to physical predictions based on the objects’ geometry. Although deviations from physical predictions in both tasks were relatively small, more detailed analyses of individual performance in the two tasks revealed mutual inconsistencies between the critical angle and COM settings. These suggest that observers may not be using their COM estimates in the physically correct manner to make judgments of physical stability.

Abstract
Perceiving 3D shape from shading and texture requires combining different, but complimentary, information about shape features extracted from 2D images. Here, we sought to predict specific regions of interest (ROIs) within images – derived from orientation flows – where each cue leads to locally better or worse shape perception. This analysis assesses whether the visual system uses orientation flows to estimate shape. A gauge figure experiment was used to evaluate shape perception for 3D objects with Lambertian shading, isotropic texture, both shading and texture, and pseudo-shaded depth maps. Participant performance was compared to image and scene-based perceptual predictors. Shape from texture ROI models incorporated surface slant and tilt, second order partial derivatives, and tangential and normal curvatures of texture orientation. Shape from shading ROI models included image based metrics, anisotropy of the second fundamental form, and surface derivatives. Results confirmed that, individually, texture and shading are not diagnostic of object shape for all locations, but local performance correlates well with ROIs predicted by first and second order shape properties. In regions that were ROI for both cues, shading and texture performed complementary functions, suggesting a common front-end based on orientation flows locally predicts both strengths and weaknesses of cues.
Abstract
Many surfaces, such as weathered rocks or tree-bark, have complex 3D relief, featuring cracks, bumps and ridges. It is not uncommon for dirt to accumulate in the concavities, which is also where shadows are most likely to occur. By contrast, convex features are exposed to light and often get buffed a lighter shade. Thus, shading and pigmentation are often spatially correlated with one another, making it computationally difficult to distinguish them. How does the visual system separate shading from pigmentation, when they are correlated? We performed a statistical analysis of complex rough surfaces under directional and diffuse illumination to characterise the relationships between shading, illumination and shape. We find that image intensities carry important information about surface curvatures, and show that the visual system uses the relationships between curvatures and intensities to distinguish between shadows and pigmentation. We also find that subjects are remarkably good at separating shadows and pigmentation even when they are highly correlated. Together, these findings provide key novel constraints on computational models of human shape from shading and lightness perception.

Abstract
Visual estimation of object stability is an ecologically important judgment that allows observers to predict an object's physical behavior. One way to measure perceived stability is by estimating the ‘critical angle’ (relative to upright) at which an object is perceived to be equally likely to fall over versus return to its upright position. However, for asymmetrical objects, the critical angle varies with the direction in which the object is tilted. Here we ask: (1) Can observers reliably track the change in critical angle as a function of tilt direction? (2) How do observers visually estimate the overall stability of an object, given the different critical angles in various directions? Observers stereoscopically viewed a rendered scene containing a slanted conical frustum, with variable aspect ratio, sitting on a table. In Exp. 1, the object was placed near the edge of the table, and rotated through one of six angles relative to this edge. Observers adjusted its tilt angle (constrained to move directly toward the edge) in order to set the critical angle. We found that their settings tracked the variation in critical angle with tilt direction remarkably well. In Exp. 2, observers viewed on each trial one of the slanted frustums from Exp. 1, along with a cylindrical object of variable aspect ratio. They adjusted the aspect ratio of the cylinder in order to match the perceived stability of the slanted frustum. The results showed that on average observers' estimates of overall stability are well predicted by the minimum critical angle across all tilt directions, but not by the mean critical angle. Observers thus reasonably appear to use the critical angle in the least stable direction in order to estimate the overall stability of an asymmetrical object.

Abstract
The visual system can infer 3D shape from orientation flows arising from both texture and shading patterns. However, these two types of flows provide fundamentally different information about surface structure. Texture flows, when derived from distinct elements, mainly signal first-order features (surface slant), whereas shading flow orientations primarily relate to second-order surface properties. It is therefore crucial for the brain to identify whether flow patterns originate from shading or texture to correctly infer shape. One possible approach would be to use 'surface appearance' (e.g. smooth gradients vs. fine-scale texture) to distinguish texture from shading. However, the structure of the flow fields themselves may indicate whether a given flow is more likely due to first- or second-order shape information. Here we test these two possibilities. We generated irregular objects ('blobs') using sinusoidal perturbations of spheres. We then derived two new objects from each blob: One whose shading flow matched the original object's texture flow, and another whose texture flow matched the original's shading flow. Using high and low frequency environment maps to render the surfaces, we were able to manipulate surface appearance independently from the flow structure. This provided a critical test of how appearance interacts with orientation flow when estimating 3D shape and revealed some striking illusions of shape. In an adjustment task, observers matched the perceived shape of a standard object to each comparison object by morphing between the generated shape surfaces. In a 2AFC task, observers were shown two manipulations for each blob and indicated which one matched a briefly flashed standard. Performance was compared to an orientation flow based model and confirmed that observers' judgments agreed with texture and shading flow predictions. Both the structure of the flow and overall appearance are important for shape perception, but appearance cues determine the inferred source of the observed flowfield.

Abstract
Humans are generally remarkably good at inferring 3D shape from distorted patterns of reflections on mirror-like objects (Fleming et al, 2004). However, there are conditions in which shape perception fails (complex planar reliefs under certain illuminations; Faisman and Langer, 2013). A good theory of shape perception should predict failures as well as successes of shape perception, so here we sought to map out systematically the conditions under which subjects fail to estimate shape from specular reflections and to understand why. To do this, we parametrically varied the spatial complexity (spatial frequency content) of both 3D relief and illumination, and measured under which conditions subjects could and could not infer shape. Specifically, we simulated surface reliefs with varying spatial frequency content and rendered them as perfect mirrors under spherical harmonic light probes with varying frequency content. Participants viewed the mirror-like surfaces and performed a depth-discrimination task. On each trial, the participants’ task was to indicate which of two locations on the surface—selected randomly from a range of relative depth differences on the object’s surface—was higher in depth. We mapped out performance as a function of both the relief and the lighting parameters. Results show that while participants were accurate within a given range for each manipulation, there also existed a range of spatial frequencies – namely very high and low frequencies – where participants could not estimate surface shape. Congruent with previous research, people were able to readily determine 3D shape using the information provided by specular reflections; however, performance was highly dependent upon surface and environment complexities. Image analysis reveals the specific conditions that subjects rely on to perform the task, explaining the pattern of errors.

Abstract
Humans are generally remarkably good at inferring 3D shape from distorted reflection patterns on mirror-like objects (Fleming et al, 2004). However, in certain conditions shape perception fails (complex planar reliefs under certain illuminations; Faisman and Langer, 2013). Here we map out systematically those conditions under which subjects fail to estimate shape from specular reflections. Specifically, we simulated surface reliefs with varying spatial frequency content and rendered them as perfect mirrors under spherical harmonic light probes with varying frequency content. The participants performed a depth discrimination task, in which they indicated which of two locations on the surface—selected randomly from a range of relative depth differences on the object’s surface—was higher in depth. Congruent with previous research, subjects were able to readily determine 3D shape using the information provided by specular reflections; however, performance was highly dependent upon surface and environment complexities. Results show that while participants were accurate within a given range for each manipulation, there also existed a range of spatial frequencies – namely very high and low frequencies – where participants could not estimate surface shape. Image analysis reveals the specific conditions that subjects rely on to perform the task, explaining the pattern of errors.

Abstract
The estimation of 3D shape from 2D images requires processing and combining many cues, including texture, shading, specular highlights and reflections. Previous research has shown that oriented filter responses ('orientation fields') may be used to perceptually reconstruct the surface structure of textured and shaded 3D objects. However, texture and shading provide fundamentally different information about 3D shape -- texture provides information about surface orientations (which depend on the first derivative of the surface depth) while shading provides information about surface curvatures (which depend on higher derivatives). In this research project, we used specific geometric transformations that preserve the informativeness of one cue's orientation fields while disturbing the other cue’s orientation fields to investigate whether oriented filter responses predict the observed strengths and weaknesses of texture and shading cues for 3D shape perception. In the first experiment, a 3D object was matched to two comparison objects, one with identical geometry and another with a subtly different pattern of surface curvatures. This transformation alters second derivatives of the surface while preserving first derivatives, so changes in the orientation fields predict higher detectability for shaded objects. This was reflected in participants' judgments and model performance. In the second experiment, observers matched the perceived shear of two objects. This transformation alters first derivatives but preserves second derivatives. Therefore, changes in the orientation fields predicted a stronger effect on the perceived shape for textured objects, which was reflected in participant and model performance. These results support a common front-end -- based on orientation fields -- that accounts for the complementary strengths and weaknesses of texture and shading cues. Neither cue is fully diagnostic of object shape under all circumstances, and neither cue is 'better' than the other in all situations. Instead, the model provides a unified account of the conditions in which cues succeed and fail.

Abstract
Physical stability is an ecologically important judgment about objects that allows observers to predict object behavior and appropriately guide motor actions to interact with them. Moreover, it is an attribute that observers can estimate from vision alone, based on an object's shape. In previous work, we have used different tasks to investigate perceived object stability, including estimation of critical angle of tilt and matching stability across objects with different shapes (VSS 2010, 2011). The ability to perform these tasks, however, does not necessarily indicate that object stability is a natural perceptual dimension. We asked whether it is possible to obtain adaptation aftereffects with perceived object stability. Does being exposed to a sequence of highly stable (bottom-heavy) objects make a test object appear less stable (and vice versa)? Our test objects were vertically elongated shapes, with a flat base and a vertical axis of symmetry. Its axis could be curved to different degrees, while keep its base horizontal. The Psi adaptive procedure (Kontsevich & Tyler, 1999) was used to estimate the "critical curvature" - the minimum axis curvature for which the test object is judged to fall over. This was estimated in three conditions: baseline (no adaptation), post-adaptation with high-stability shapes (mean critical angle: 63.5 degrees), and post-adaptation with low-stability shapes (mean critical angle: 16.7 degrees). In the adaptation conditions, observers viewed a sequence of 40 distinct adapting shapes. Following this, a test shape was shown, and observers indicated whether the object would stay upright or fall over. Adaptation was "topped up" after every test shape. Most observers exhibited an adaptation to object stability: the estimated critical curvature was lower following adaptation to high-stability shapes, and higher following adaptation to low-stability shapes. The results suggest that object stability may indeed be a natural perceptual variable.

Abstract
Visual estimation of object stability is an ecologically important judgment that allows observers to predict objects' physical behavior. Previously we have used the 'critical angle' of tilt to measure perceived object stability (VSS 2010; VSS 2011). The current study uses a different paradigm—measuring the critical extent to which an object can "stick out" over a precipitous edge before falling off. Observers stereoscopically viewed a rendered scene containing a 3D object placed near a table’s edge. Objects were slanted conical frustums that varied in their slant angle, aspect ratio, and direction of slant (pointing toward/away from the edge). In the stability task, observers adjusted the horizontal position of the object relative to the precipitous edge until it was perceived to be in unstable equilibrium. In the CoM task, they adjusted the height of a small ball probe to indicate perceived CoM. Results exhibited a significant effect of all three variables on stability judgments. Observers underestimated stability for frustums slanting away from the edge, and overestimated stability when slanting toward it, suggesting a bias toward the center of the supporting base. However, performance was close to veridical in the CoM task—providing further evidence of mutual inconsistency between perceived stability and CoM judgments.

Abstract
Repeated haptic exploration of a surface with curvature results in an adaptation effect, such that flat surfaces feel curved in the opposite direction of the explored surface. Previous studies used real objects and involved contact of skin on surface with no visual feedback. To what extent do cutaneous, proprioceptive, and visual cues play a role in the neural representation of surface curvature? The current study used a Personal Haptic Interface Mechanism (PHANToM) force-feedback device to simulate physical objects that subjects could explore with a stylus. If haptic aftereffect is observed in exploration of virtual surfaces, it suggests neural representations of curvature based solely on proprioceptive input. If visual input plays a role in the absence of haptic convexity/concavity, it would provide evidence for a visual input to the neural haptic representation. Method. Baseline curvature discrimination was obtained from subjects who explored a virtual surface with the stylus and reported whether it was concave or convex. In Experiment 1, subjects adapted to a concave or convex curvature (+-3.2 m−1) and reported the curvature of a test surface (ranging from −1.6 m^−1 to 1.6 m^−1). In Experiment 2, subjects adapted with their left hands and tested with their right (intermanually). In Experiment 3, subjects were given visual feedback on a computer screen that the trajectory of the stylus tip was a curved surface, while the haptic surface was flat. Results. In Experiment 1, subjects showed a strong curvature aftereffect, indicating that proprioceptive input alone is sufficient. Subjects in Experiment 2 showed weaker but significant adaptation, indicating a robust neural representation across hands. No aftereffect was found with solely visual curvature input in Experiment 3, suggesting that the neural representation is not affected by synchronized visual feedback, at least when two modalities do not agree. Implications for visual-haptic representations will be discussed.

Abstract
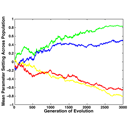
A remarkable characteristic of human perceptual systems is the ability to recognize the goals and intentions of other living things – "intelligent agents" – on the basis of their actions or patterns of motion. We use this ability to anticipate the behavior of agents in the environment, and better inform our decision making. The aim of this project is to develop a theoretical model of the perception of intentions, shedding light onto both the function of the human (biological) perceptual system, and the design of computational models that drive artificial systems (robots). To this end, an interdisciplinary group of IGERT students created a novel virtual environment populated by intelligent autonomous agents, and endowed these agents with human-like capacities: goals, real-time perception, memory, planning, and decision making. One phase of the project focused on the perceptual judgments of human observers watching the agents. Experimental subjects’ judgments of the agents’ intentions were accurate and in agreement with one another. In another experiment, the agents were programmed to evolve through many "generations" as they competed for "food" and survival within a game-like framework. We examined whether the ability of human observers to classify and interpret the intentions of agents improved as the behavior of successive agent generations became more optimal. Our results show that (a) dynamic virtual environments can be developed that embody the essential perceptual cues to the intentions of intelligent agents, and (b) when studied in such environments, human perception of the intentions of intelligent agents proves to be accurate, rational and rule-governed.

Abstract
Comprehension of goal-directed, intentional motion is an important but understudied visual function. To study it, we created a two-dimensional virtual environment populated by independently-programmed autonomous virtual agents. These agents (depicted as oriented triangles) navigate the environment, playing a game with a simple goal (collecting "food" and bringing it back to a cache location). The agents' behavior is controlled by a small number of distinct states or subgoals–including exploring, gathering food, attacking, and fleeing–which can be thought of as "mental" states. Our subjects watched short vignettes of a small number of agents interacting. We studied their ability to detect and classify agents' mental states on the basis of their motions and interactions. In one version of our experiment, the four mental states were explicitly explained, and subjects were asked to continually classify one target agent with respect to these states, via keypresses. At each point in time, we were able to compare subjects' responses to the "ground truth" (the actual state of the target agent at that time). Although the internal state of the target agent is inherently hidden and can only be inferred, subjects reliably classified it: "ground truth" accuracy was 52%–more than twice chance performance. Interestingly, the percentage of time when subjects' responses were in agreement with one another (63%) was higher than accuracy with respect to "ground truth." In a second experiment, we allowed subjects to invent their own behavioral categories based on sample vignettes, without being told the nature (or even the number) of distinct states in the agents' actual programming. Even under this condition, the number of perceived state transitions was strongly correlated with the number of actual transitions made by a target agent. Our methods facilitate a rigorous and more comprehensive study of the "psychophysics of intention." For details and demos, see http://ruccs.rutgers.edu/~jacob/demos/imps/


Abstract
Research on 3D shape has focused largely on the perception of local geometric properties, such as surface depth, orientation, or curvature. Relatively little is known about how the visual system organizes local measurements into global shape representations. Here, we investigated how the perceptual organization of shape affects the perception of physical stability of 3D objects. Estimating stability is important for predicting object behavior and guiding motor actions, and requires the observer to integrate information from the entire object. Observers stereoscopically viewed a rendered scene containing a 3D shape placed near the edge of a table. They adjusted the tilt of the object over the edge to set its perceived critical angle, i.e., the angle at which the object is equally likely to fall off the table vs. return to its upright position. The shapes were conical frustums with one of three aspect ratios—either by themselves, or with a part protruding from the side. When present, the boundaries between the part and the frustum were either sharp or smooth. Importantly, the part either faced directly toward the edge of the table or directly away from it. Observers were close to the physical prediction for tall/narrow shapes, but with decreasing aspect ratio (shorter/wider shapes), there was a tendency to underestimate the critical angle. With this bias factored out, we found that errors were mostly positive when the part faced toward the table's edge, and mostly negative when facing the opposite direction. These results are consistent with observers underestimating the physical contribution of the attached part. Thus, in making judgments of physical stability observers tend to down-weight the influence of attached part—consistent with a robust-statistics approach to determining the influence of a part on global visual estimates (Cohen & Singh, 2006; Cohen et al., 2008).

Abstract
Previous research on statistical perception has shown that subjects are very good at perceptually estimating first-order statistical properties of sets of similar objects (such as the mean size of a set of disks). However, it is unlikely that our mental representation of the world includes only a list of mean estimates of various attributes. Work on motor and perceptual decisions, for example, suggests that observers are implicitly aware of their own motor / perceptual uncertainty, and are able to combine it with an experimenter-specified loss function in a near-optimal manner. The current study investigated the representation of variance by measuring difference thresholds for orientation variance of sets of narrow isosceles triangles with relatively large Standard Deviations (SD): 10, 20, 30 degrees; and for different sample sizes (N): 10, 20, 30 samples. Experimental displays consisted of multiple triangles whose orientations were specified by a von Mises distribution. Observers were tested in a 2IFC task in which one display had a base SD, and the other, test, display had a SD equal to +/−10, +/−30, +/−50, and +/−70% of the base SD. Observers indicated which interval had higher orientation variance. Psychometric curves were fitted to observer responses and difference thresholds were computed for the 9 conditions. The results showed that observers can estimate variance in orientation with essentially no bias. Although observers are thus clearly sensitive to variance, their sensitivity is not as high as for the mean. The relative thresholds (difference threshold SD / base SD) exhibited little dependence on base SD, but increased greatly (from ∼20% to 40%) as sample size decreased from 30 to 10. Comparing the σ of the cumulative normal fits to the standard error of SD, we found that the estimated σ's were on average about 3 times larger than the corresponding standard errors.

Abstract
This experiment investigated static information transfer (IT) in a stiffness identification experiment. Past research on stiffness perception has only measured the Weber fractions. In many applications where haptic virtual environments are used for data perceptualization, both the ability to discriminate stiffness (Weber fraction) and the number of correctly identifiable stiffness levels (2^IT) are important for selecting rendering parameters. Ten participants were asked to tap a virtual surface vertically using a customdesigned haptic force-feedback device and identify the stiffness level. Five stiffness values in the range 0.2 to 3.0N/mm were used. The virtual surface was modeled as a linear elastic spring and exerted an upward resistive force equaling the product of stiffness and penetration depth whenever it was penetrated. A total of 250 trials were collected per participant. The average static IT was 1.57 bits, indicating that participants were able to correctly identify about three stiffness levels.
Abstract
We will showcase how a specular object’s image is dependent upon the way the reflected environment interacts with the the object’s geometry and how its perceived shape depends upon motion and the frequency content of the environment. Demos include perceived non-rigid deformation of shape and changes in material percept.

Abstract
A mirrored object reflects a distorted world. The distortions depend on the object's surface and act as points of correspondence when it moves. We demonstrate how the perceived speed of a rotating mirrored object is affected by rotation of the environment and present an interesting case of perceived non-rigid deformation.

Abstract
Vision research generally focuses on the currently visible surface properties of objects, such as color, texture, luminance, orientation, and shape. In addition, however, observers can also visually predict the physical behavior of objects, which often requires inferring the action of hidden forces, such as gravity and support relations. One of the main conclusions from the naive physics literature is that people often have inaccurate physical intuitions; however, more recent research has shown that with dynamic simulated displays, observers can correctly infer physical forces (e.g., timing hand movements to catch a falling ball correctly takes into account Newton’s laws of motion). One ecologically important judgment about physical objects is whether they are physically stable or not. This research project examines how people perceive physical stability and addresses (1) How do visual estimates of stability compare to physical predictions? Can observers track the influence of specific shape manipulations on object stability? (2) Can observers match stability across objects with different shapes? How is the overall stability of an object estimated? (3) Are visual estimates of object stability subject to adaptation effects? Is stability a perceptual variable? The experimental findings indicate that: (1) Observers are able to judge the stability of objects quite well and are close to the physical predictions on average. They can track how changing a shape will affect the physical stability; however, the perceptual influence is slightly smaller than physically predicted. (2) Observers can match the stabilities of objects with different three-dimensional shapes -- suggesting that object stability is a unitary dimension -- and their judgments of overall stability are strongly biased towards the minimum critical angle. (3) The majority of observers exhibited a stability adaptation aftereffect, providing evidence in support of the claim that stability may be a perceptual variable.

Abstract
Recent research has shown that participants are very good at perceptually estimating summary statistics of sets of similar objects (e.g., Ariely, 2001; Chong & Treisman, 2003; 2005). While the research has focused on first-order statistics (e.g., the mean size of a set of discs), it is unlikely that a mental representation of the world includes only a list of mean estimates (or expected values) of various attributes. Therefore, a comprehensive theory of perceptual summary statistics would be incomplete without an investigation of the representation of second-order statistics (i.e., variance). Two experiments were conducted to test participants' ability to discriminate samples that differed in orientation variability. Discrimination thresholds and points of subjective equality for displays of oriented triangles were measured in Experiment 1. The results indicated that participants could discriminate variance without bias and that participant sensitivity (measured via relative thresholds, i.e., Weber fractions) was dependent upon sample size but not baseline variance. Experiment 2 investigated whether participants used a simpler second-order statistic, namely, sample range to discriminate dispersion in orientation. The results of Experiment 2 showed that variance was a much better predictor of performance than sample range. Taken together, the experiments suggest that variance information is part of the visual system's representation of scene variables. However, unlike the estimation of first-order statistics, the estimation of variance depends crucially on sample size.





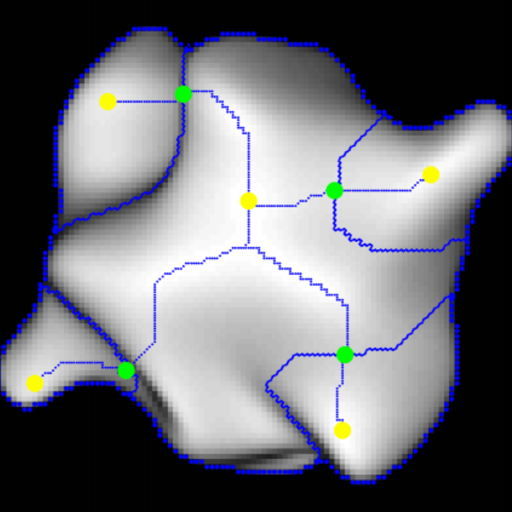
Abstract
We exploit a key result from visual psychophysics---that individuals perceive shape qualitatively---to develop the use of a geometrical/topological “invariant” (the Morse--Smale complex) relating image structure with surface structure. Differences across individuals are minimal near certain configurations such as ridges and boundaries, and it is these configurations that are often represented in line drawings. In particular, we introduce a method for inferring a qualitative three-dimensional shape from shading patterns that link the shape-from-shading inference with shape-from-contour inference. For a given shape, certain shading patches approach “line drawings” in a well-defined limit. Under this limit, and invariably with respect to rendering choices, these shading patterns provide a qualitative description of the surface. We further show that, under this model, the contours partition the surface into meaningful parts using the Morse--Smale complex. These critical contours are the (perceptually) stable parts of this complex and are invariant over a wide class of rendering models. Intuitively, our main result shows that critical contours partition smooth surfaces into bumps and valleys, in effect providing a scaffold on the image from which a full surface can be interpolated.
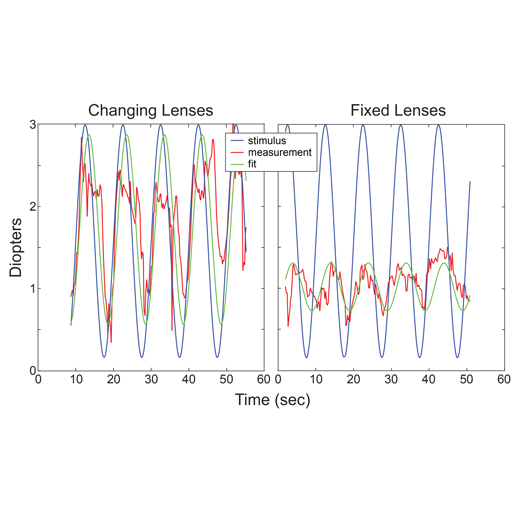
Abstract
Head-mounted displays (HMDs) often cause discomfort and even nausea. Improving comfort is therefore one of the most significant challenges for the design of such systems. In this paper, we evaluate the effect of different HMD display configurations on discomfort. We do this by designing a device to measure human visual behavior and evaluate viewer comfort. In particular, we focus on one known source of discomfort: the vergence-accommodation (VA) conflict. The VA conflict is the difference between accommodative and vergence response. In HMDs the eyes accommodate to a fixed screen distance while they converge to the simulated distance of the object of interest, requiring the viewer to undo the neural coupling between the two responses. Several methods have been proposed to alleviate the VA conflict, including Depth-of-Field (DoF) rendering, focus-adjustable lenses, and monovision. However, no previous work has investigated whether these solutions actually drive accommodation to the distance of the simulated object. If they did, the VA conflict would disappear, and we expect comfort to improve. We design the first device that allows us to measure accommodation in HMDs, and we use it to obtain accommodation measurements and to conduct a discomfort study. The results of the first experiment demonstrate that only the focus-adjustable-lens design drives accommodation effectively, while other solutions do not drive accommodation to the simulated distance and thus do not resolve the VA conflict. The second experiment measures discomfort. The results validate that the focus-adjustable-lens design improves comfort significantly more than the other solutions.
Abstract
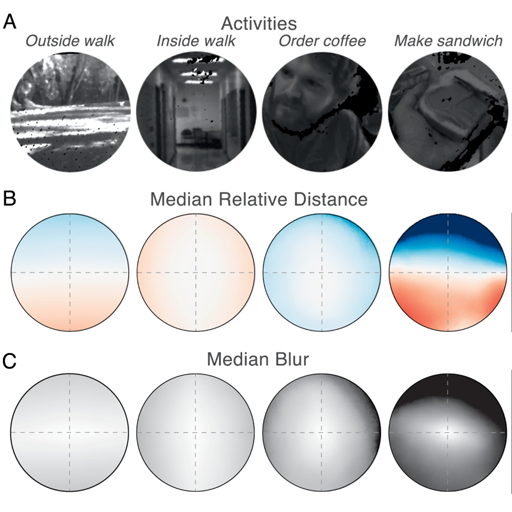
Blur from defocus can be both useful and detrimental for visual perception: It can be useful as a source of depth information and detrimental because it degrades image quality. We examined these aspects of blur by measuring the natural statistics of defocus blur across the visual field. Participants wore an eye-and-scene tracker that measured gaze direction, pupil diameter, and scene distances as they performed everyday tasks. We found that blur magnitude increases with increasing eccentricity. There is a vertical gradient in the distances that generate defocus blur: Blur below the fovea is generally due to scene points nearer than fixation; blur above the fovea is mostly due to points farther than fixation. There is no systematic horizontal gradient. Large blurs are generally caused by points farther rather than nearer than fixation. Consistent with the statistics, participants in a perceptual experiment perceived vertical blur gradients as slanted top-back whereas horizontal gradients were perceived equally as left-back and right-back. The tendency for people to see sharp as near and blurred as far is also consistent with the observed statistics. We calculated how many observations will be perceived as unsharp and found that perceptible blur is rare. Finally, we found that eye shape in ground-dwelling animals conforms to that required to put likely distances in best focus.
Abstract
The depth ordering of two surfaces, one occluding the other, can in principle be determined from the correlation between the occlusion border's blur and the blur of the two surfaces. If the border is blurred, the blurrier surface is nearer; if the border is sharp, the sharper surface is nearer. Previous research has found that observers do not use this informative cue. We reexamined this finding. Using a multiplane display, we confirmed the previous finding: Our observers did not accurately judge depth order when the blur was rendered and the stimulus presented on one plane. We then presented the same simulated scenes on multiple planes, each at a different focal distance, so the blur was created by the optics of the eye. Performance was now much better, which shows that depth order can be reliably determined from blur information but only when the optical effects are similar to those in natural viewing. We asked what the critical differences were in the single- and multiplane cases. We found that chromatic aberration provides useful information but accommodative microfluctuations do not. In addition, we examined how image formation is affected by occlusions and observed some interesting phenomena that allow the eye to see around and through occluding objects and may allow observers to estimate depth in da Vinci stereopsis, where one eye's view is blocked. Finally, we evaluated how accurately different rendering and displaying techniques reproduce the retinal images that occur in real occlusions. We discuss implications for computer graphics.

Abstract
A failure of adaptive inference—misinterpreting available sensory information for appropriate perception and action—is at the heart of clinical manifestations of schizophrenia, implicating key subcortical structures in the brain including the hippocampus. We used high-resolution, three-dimensional (3D) fractal geometry analysis to study subtle and potentially biologically relevant structural alterations (in the geometry of protrusions, gyri and indentations, sulci) in subcortical gray matter (GM) in patients with schizophrenia relative to healthy individuals. In particular, we focus on utilizing Fractal Dimension (FD), a compact shape descriptor that can be computed using inputs with irregular (i.e., not necessarily smooth) surfaces in order to quantify complexity (of geometrical properties and configurations of structures across spatial scales) of subcortical GM in this disorder. Probabilistic (entropy-based) information FD was computed based on the box-counting approach for each of the seven subcortical structures, bilaterally, as well as the brainstem from high-resolution magnetic resonance (MR) images in chronic patients with schizophrenia (n = 19) and age-matched healthy controls (n = 19) (age ranges: patients, 22.7–54.3 and healthy controls, 24.9–51.6 years old). We found a significant reduction of FD in the left hippocampus (median: 2.1460, range: 2.07–2.18 vs. median: 2.1730, range: 2.15–2.23, p < 0.001; Cohen’s effect size, U3 = 0.8158 (95% Confidence Intervals, CIs: 0.6316, 1.0)), the right hippocampus (median: 2.1430, range: 2.05–2.19 vs. median: 2.1760, range: 2.12–2.21, p = 0.004; U3 = 0.8421 (CIs: 0.5263, 1)), as well as left thalamus (median: 2.4230, range: 2.40–2.44, p = 0.005; U3 = 0.7895 (CIs: 0.5789, 0.9473)) in schizophrenia patients, relative to healthy individuals. Our findings provide in-vivo quantitative evidence for reduced surface complexity of hippocampus, with reduced FD indicating a less complex, less regular GM surface detected in schizophrenia.

Abstract
MatMix 1.0 is a novel material probe we developed for quantitatively measuring visual perception of materials. We implemented optical mixing of four canonical scattering modes, represented by photographs, as the basis of the probe. In order to account for a wide range of materials, velvety and glittery (asperity and meso-facet scattering) were included besides the common matte and glossy modes (diffuse and forward scattering). To test the probe, we conducted matching experiments in which inexperienced observers were instructed to adjust the modes of the probe to match its material to that of a test stimulus. Observers were well able to handle the probe and match the perceived materials. Results were robust across individuals, across combinations of materials, and across lighting conditions. We conclude that the approach via canonical scattering modes and optical mixing works well, although the image basis of our probe still needs to be optimized. We argue that the approach is intuitive, since it combines key image characteristics in a “painterly” approach. We discuss these characteristics and how we will optimize their representations.
Abstract
Objects in our environment are subject to manifold transformations, either of the physical objects themselves or of the object images on the retina. Despite drastic effects on the objects’ physical appearances, we are often able to identify stable objects across transformations and have strong subjective impressions of the transformations themselves. This suggests the brain is equipped with sophisticated mechanisms for inferring both object constancy, and objects’ causal history. We employed a dot-matching task to study in geometrical detail the effects of rigid transformations on representations of shape and space. We presented an untransformed ‘base shape’ on the left side of the screen and its transformed counterpart on the right (rotated, scaled, or both). On each trial, a dot was superimposed at a given location on the contour (Experiment 1) or within and around the shape (Experiment 2). The participant’s task was to place a dot at the corresponding location on the right side of the screen. By analyzing correspondence between responses and physical transformations, we tested for object constancy, causal history, and transformation of space. We find that shape representations are remarkably robust against rotation and scaling. Performance is modulated by the type and amount of transformation, as well as by contour saliency. We also find that the representation of space within and around a shape is transformed in line with the shape transformation, as if shape features establish an object-centered reference frame. These findings suggest robust mechanisms for the inference of shape, space and correspondence across transformations.

Abstract
When we perceive the shape of an object, we can often make many other inferences about the object, derived from its shape. For example, when we look at a bitten apple, we perceive not only the local curvatures across the surface, but also that the shape of the bitten region was caused by forcefully removing a piece from the original shape (excision), leading to a salient concavity or negative part in the object. However, excision is not the only possible cause of concavities or negative parts in objects—for example, we do not perceive the spaces between the fingers of a hand to have been excised. Thus, in order to infer excision, it is not sufficient to identify concavities in a shape; some additional geometrical conditions must also be satisfied. Here, we studied the geometrical conditions under which subjects perceived objects as been bitten, as opposed to complete shapes. We created 2-D shapes by intersecting pairs of irregular hexagons and discarding the regions of overlap. Subjects rated the extent to which the resulting shapes appeared to be bitten or whole on a 10-point scale. We find that subjects were significantly above chance at identifying whether shapes were bitten or whole. Despite large intersubject differences in overall performance, subjects were surprisingly consistent in their judgments of shapes that had been bitten. We measured the extent to which various geometrical features predict subjects' judgments and find that the impression that an object is bitten is strongly correlated with the relative depth of the negative part. Finally, we discuss the relationship between excision and other perceptual organization processes such modal and amodal completion, and the inference of other attributes of objects, such as the material properties.

Abstract
Previous research has found performance for several egocentric tasks to be superior on physically large displays relative to smaller ones, even when visual angle is held constant. This finding is believed to be due to the more immersive nature of large displays. In our experiment, we examined if using a large display to learn a virtual environment (VE) would improve egocentric knowledge of the target locations. Participants learned the location of five targets by freely exploring a desktop large-scale VE of a city on either a small (25" diagonally) or large (72" diagonally) screen. Viewing distance was adjusted so that both displays subtended the same viewing angle. Knowledge of the environment was then assessed using a head-mounted display in virtual reality, by asking participants to stand at each target and paint at the other unseen targets. Angular pointing error was significantly lower when the environment was learned on a 72" display. Our results suggest that large displays are superior for learning a virtual environment and the advantages of learning an environment on a large display may transfer to navigation in the real world.

Abstract
Previous research has found performance for several egocentric tasks to be superior on physically large displays relative to smaller ones, even when visual angle is held constant. This finding is believed to be due to the more immersive nature of large displays. In our experiment, we examined if using a large display to learn a virtual environment (VE) would improve egocentric knowledge of the target locations. Participants learned the location of five targets by freely exploring a desktop large-scale VE of a city on either a small (25" diagonally) or large (72" diagonally) screen. Viewing distance was adjusted so that both displays subtended the same viewing angle. Knowledge of the environment was then assessed using a head-mounted display in virtual reality, by asking participants to stand at each target and paint at the other unseen targets. Angular pointing error was significantly lower when the environment was learned on a 72" display. Our results suggest that large displays are superior for learning a virtual environment and the advantages of learning an environment on a large display may transfer to navigation in the real world.
Abstract
Tactile displays to enhance virtual and real environments are becoming increasingly common. Extending previous studies, we explored spatial localization of individual sites on a dense tactile array worn on the observer?s trunk, and their interaction with simultaneously-presented visual stimuli in an isomorphic display. Stimuli were composed of individual vibratory sites on the tactile array or projected flashes of light. In all cases, the task for the observer was to identify the location of the target stimulus, whose modality was defined for that session. In the multimodal experiment, observers were also required to identify the quality of a stimulus presented in the other modality (the "distractor"). Overall, performance was affected by the location of the target within the array. Having to identify the quality of a simultaneous stimulus in the other modality reduced both target accuracy and response time, but these effects did not seem to be a function of the relative location of the distractor.

Abstract
Based on the theory of conceptual metaphor we investigated the evaluative consequences of a match (or mismatch) of different conceptual relations (good vs. bad; abstract vs. concrete) with their corresponding spatial relation (UP vs. DOWN). Good and bad words that were either abstract or concrete were presented in an up or down spatial location. Words for which the conceptual dimensions matched the spatial dimension were evaluated most favorably. When neither of the two conceptual dimensions matched the spatial dimension, ratings were not as favorable as when the dimensions did match, but were still significantly more favorable than when one conceptual category was matched with the spatial category (e.g., UP and abstract), while the other one was not (e.g., UP and bad). Results suggest that a metacognitive feeling of fluency can produce an additional layer of evaluative information that is independent of actual stimulus valence.
Abstract
Although tactile acuity has been explored for touch stimuli, vibrotactile resolution on the skin has not. In the present experiments, we explored the ability to localize vibrotactile stimuli on a linear array of tactors on the forearm. We examined the influence of a number of stimulus parameters, including the frequency of the vibratory stimulus, the locations of the stimulus sites on the body relative to specific body references or landmarks, the proximity among driven loci, and the age of the observer. Stimulus frequency and age group showed much less of an effect on localization than was expected. The position of stimulus sites relative to body landmarks and the separation among sites exerted the strongest influence on localization accuracy, and these effects could be mimicked by introducing an "artificial" referent into the tactile array.